full automation of data engineering and technical data governance
IOblend is a drag and drop, low code/no code data pipeline accelerator with in-built engine and DataOps
Greatly simplifies all Data Engineering and Data Management tasks required to operate an enterprise level data estate
Unique powerful engine atop of Apache Spark™ capable of processing over 10m transactions per second
Easy to use and fully flexible – create and manage your data estate to its full potential. Implement complex data migrations and federated data architectures (Data Meshes) much faster than with traditional methods
Offers true real-time data streaming from any data source
IOblend - the basics
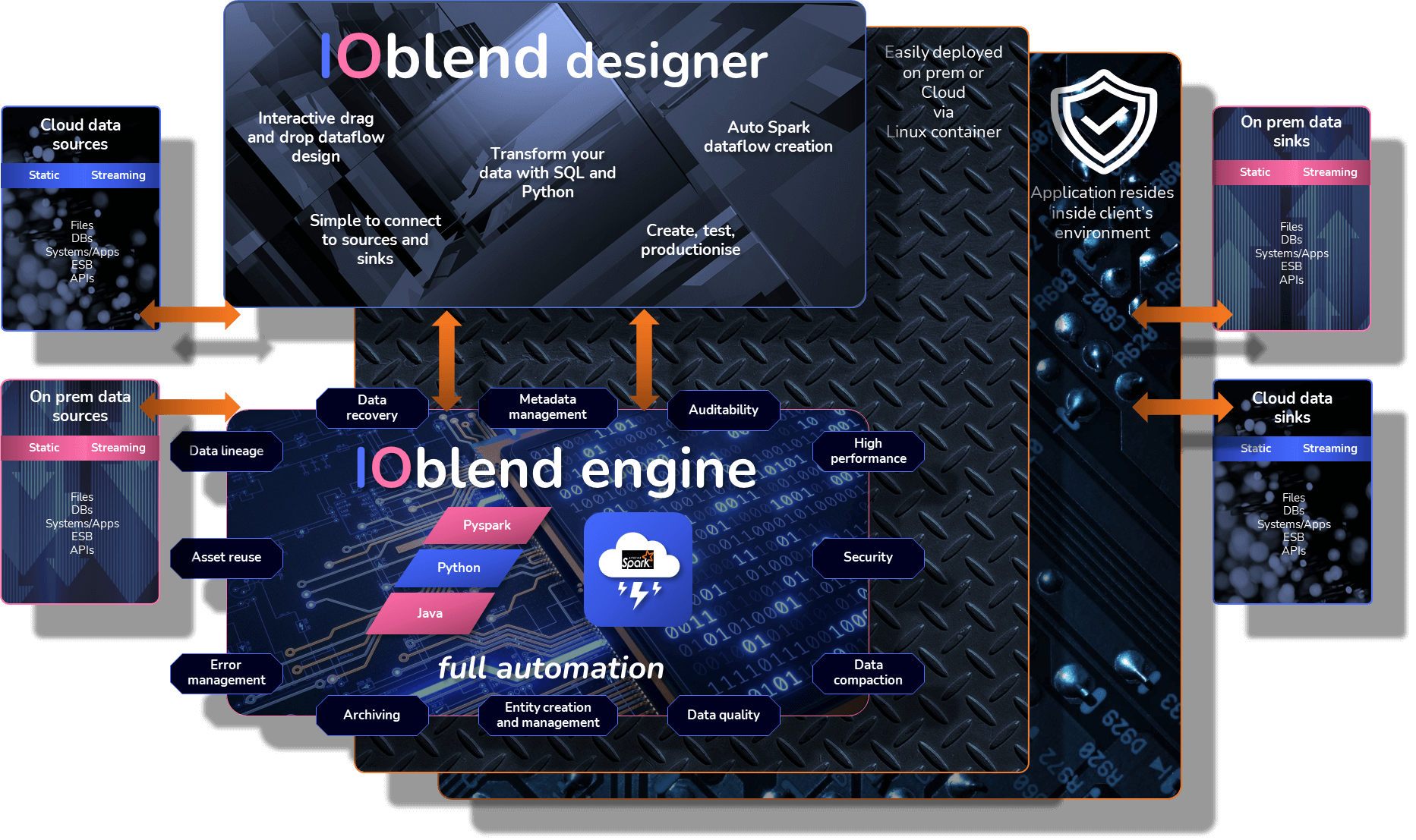
IOblend has two core components: IOblend Designer and IOblend Engine
IOblend Designer is a desktop GUI for interactively designing, building and testing data pipeline DAGs. This will produce the IOblend metadata describing the data pipelines that need to be executed
IOblend Engine: The heart of IOblend that takes IOblend data pipeline metadata and converts it into spark streaming jobs to be executed on any Spark cluster
IOblend comes in two flavours: IOblend Developer Suite and IOblend Enterprise Suite
IOblend Developer Suite:
Both the IOblend Designer and IOblend Engine are installed on a developer’s desktop/laptop. IOblend automatically creates a local Spark environment for the IOblend Engine to work with and executes pipelines created by IOblend Designer
Although the IOblend engine is running on your local machine, it can still connect to any Cloud or On-prem source you have access to pull the data from and use within your data pipeline. Likewise, it also writes the results of a data pipeline to any Cloud or On-prem structure that you have access to. Data pipelines can only be executed from the Designer
IOblend Enterprise Suite:
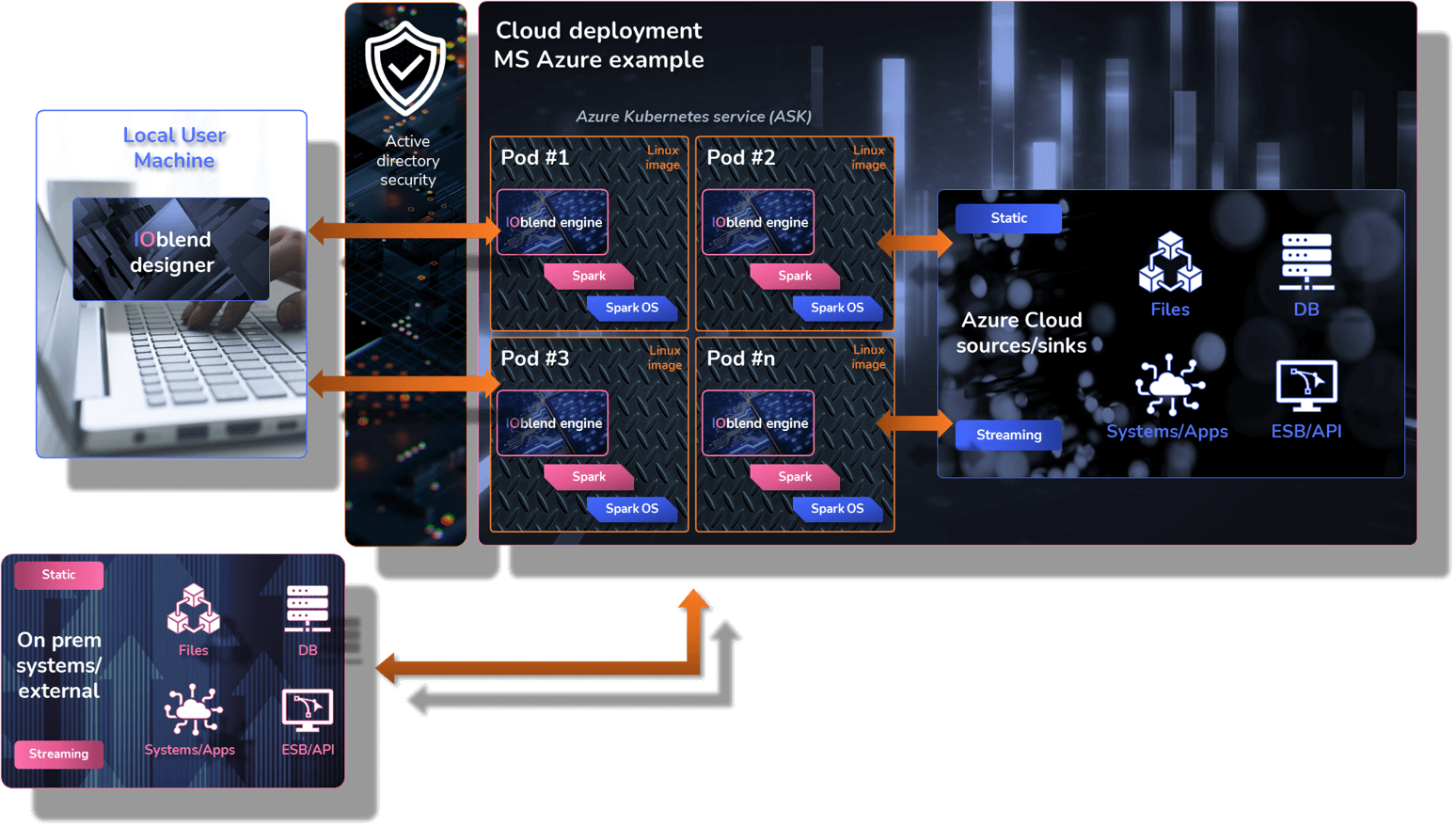
Similar to the Development Suite but this time you have a remote IOblend Engine, packaged to run on any Cloud or On-prem Spark environment. IOblend Designer will generate ‘run’ files that can be executed/scheduled to run in your enterprise Spark infrastructure. IOblend designer can be connected to either the local IOblend Engine or the remote IOblend engine for development and testing. The IOblend run files can be scheduled by any scheduling software such as Airflow.
IOblend supports collaborative development and pipeline versioning.
All IOblend data pipelines are stored as JSON metadata files, which means they can be placed in any code repository and versioned, just like standard software development.
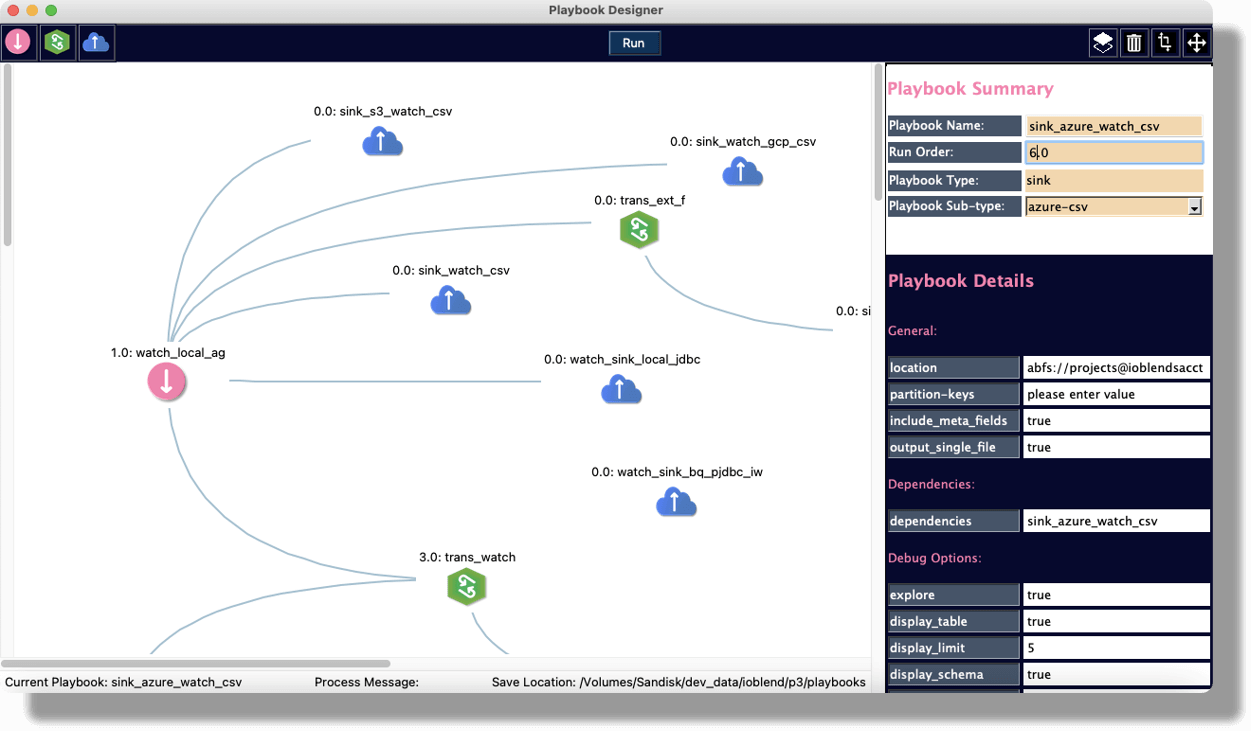
IOblendDesigner is a visual tool for developing and managing dataflows
IOblendEngine is a proprietary framework that sits atop of Apache Spark™ and enhances it with advanced features like complex transforms and true streaming from any source
Dataflows are defined in playbooks, which store configuration and the business logic of the dataflows
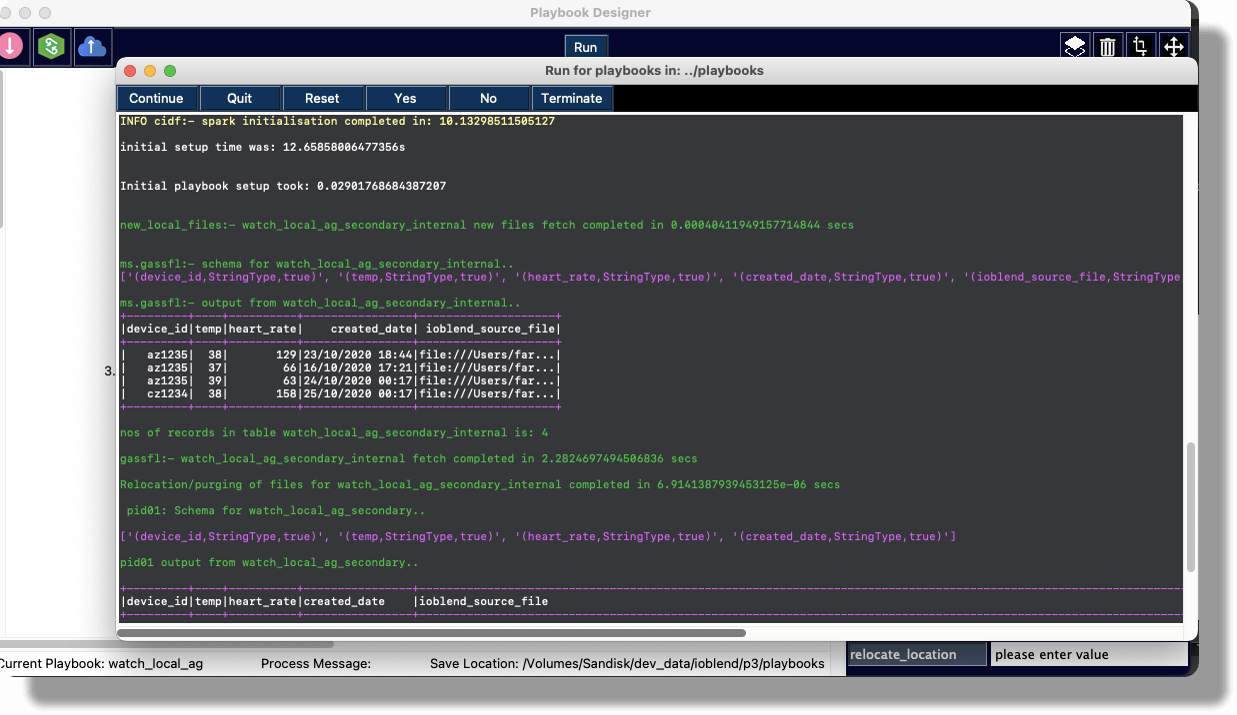
The engine dynamically converts the playbooks to Apache Spark™ streaming jobs and executes them efficiently without the need to code
IOblend seamlessly flows data in both directions, across all environments and in real time, giving the full freedom to manage your data as required
IOblend resides entirely inside the client’s environment, inheriting security protocols for a complete peace of mind
The sleek and intuitive front end interface allows for easy dataflow engineering
You can add/remove as many dataflow components as required, build up and test them one at a time, in sequence or its entirety, and create fully productionised dataflows in minutes, not days – without the knowledge of Spark coding skills. Just use SQL (or Python for complex use cases, e.g. API integration, data science models) for your data transforms
Create advanced dataflows for streaming or batch data from any source and sink to any environment prem/cloud/hybrid environments – and flow your data back to source just as easily as required
We have templated and annotated all dataflow options to make it totally hassle free for you to create state-of-the-art data estates, no matter how complex they might be
In Dev mode, you can inspect each step of your dataflow development as you progress
Pause, amend and update your sources, transforms and sinks while running dataflows live, without the need to stop the job while you work on it
Metadata is automatically managed and record-level data lineage is applied, and the data is deduped – all in memory
You can easily see and export the schemas (current and all history)
It supports your enterprise data governance initiatives
Template and save your dataflows for later reuse and get your entire analytical community working with the shared knowledge to save time and effort
Automatically convert business logic into in-memory distributed compute transforms – for fast data transforms
Automatically handles Change Data Capture
COMPLEX TRANSFORMS
Join unlimited streaming sources Supports inner and outer joins of streaming sources Supports complex aggregates of all streaming sources Ability to automatically replay all transforms associated with late arriving data
PROCESS FLOW MANAGEMENT
Orchestrate relationships and dependencies between multiple dataflow components (sources, transforms, sinks)
SCHEDULING AND MONITORING
Easily manage the execution and scheduling of all pipelines with your preferred scheduler
DATA SOURCES, TRANSFORMS AND SINKS
Connect to any data source, Cloud or file system. Automatically convert SQL and Python business logic scripts into in-memory distributed compute transforms, flowing your data freely to, from and across multiple clouds, on-prem and edges in real time
DATA LINEAGE
Automatic data lineage, slowly changing dimensions, auditing metadata and determining and alerting to schema changes throughout the dataflow
METADATA CATALOGUE
Automatically creates a searchable catalogue for all schemas and dataflows encouraging reuse
AUTOMATIC DATA ESTATE MANAGEMENT
Automatically build and maintain your data lakes and warehouses on any environment
Implements ACID transactions and other traditional data warehouse features automatically on any data engine
ERROR MANAGEMENT
Automatic logging and monitoring of errors and associated directed alerts
ENVIRONMENTS
Run it on any Cloud, on premise and hybrid environments, flowing and managing data seamlessly across all of them
DIGITAL TRANSFORMATION MADE SIMPLE
Implement robust, production-grade Data Mesh architectures with minimal effort and expense. Seamlessly integrate with your current suite of analytical tools, systems, and dashboards, but now make them a robust and integral part with the rest of your modern data estate
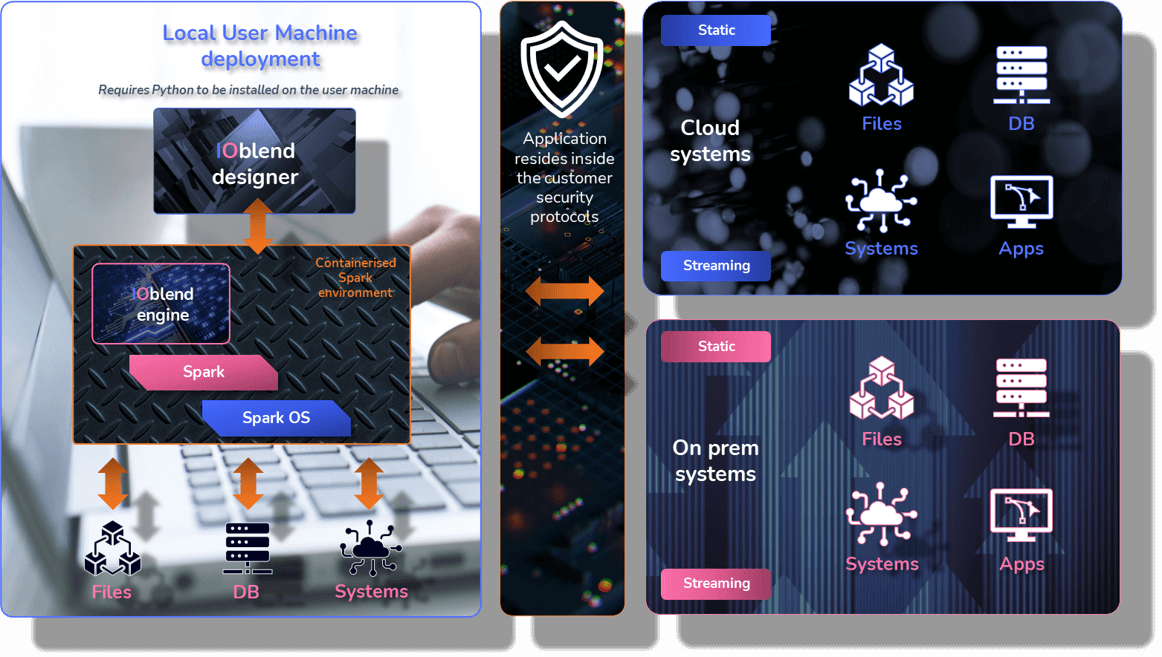
Local machine deployment is best suited for dataflow development
IOblend ships with a containerisedSparkenvironment, so it works out of the box – no need for developers, analysts and data scientists to build local Spark environments
The software connects to the client’s data systems via the existing security protocols, so no data is ever exposed externally